Discover how to tackle data engineering challenges by streamlining data extraction and ingestion processes to unlock actionable insights that drive business growth.

Data extraction serves as the primary starting point for any data engineering pipeline.
Sometimes referred to as data ingestion or importing data, this step lays the foundation for downstream processes.
Whether you follow the Extract-Transform-Load (ETL) or Extract-Load-Transform (ELT) paradigm, data extraction is the crucial first step.
Organizations in today's data-driven world depend on a wide range of data sources, including data lakes, databases, APIs, web pages, files and more.
Extracting data from such diverse sources can be challenging, especially when dealing with complex or frequently-changing structures.
Inefficient data extraction may result in incomplete or outdated information, which directly impacts the quality of your insights and decision-making.
Solutions to Inefficient Data Extraction
💡 Tip: Avoid building a proprietary data extraction platform from scratch unless absolutely necessary, for more complex scenarios. In most cases, such an approach consumes significant time and resources without providing sufficient returns-on-investment.
Focus instead on leveraging existing powerful solutions and adapting them to your unique requirements.
Maximize the use of pre-built capabilities, such as open-source libraries, frameworks, cloud services and APIs.
After making the most of such pre-built solutions, you can then build out your custom capabilities on top of the pre-built solutions.
#1. Leverage a Cloud-Agnostic Data Orchestration Platform
Start by exploring data orchestration platforms like Fivetran, Matillion and Stitch, which offer several benefits.
One key benefit of such data orchestration platforms is that they are cloud-agnostic. So you can use them for a single cloud or multiple clouds without having to commit to one cloud over the other.
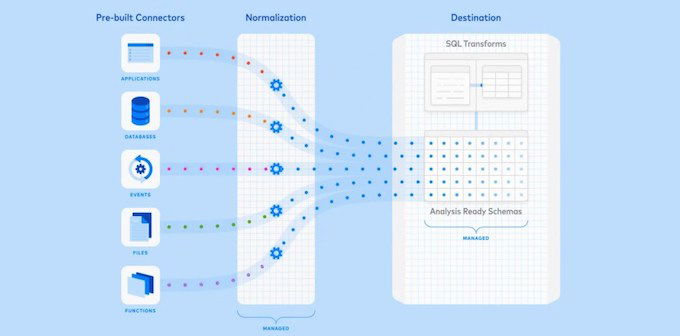
Such platforms give you the freedom to switch between different cloud providers or utilize a multi-cloud strategy.
Additional benefits of such cloud-agnostic data orchestration platforms are:
- Simplified Data Extraction: They offer pre-built connectors for numerous data sources, making it easier to extract data from various sources without the need for extensive coding.
- Scalability and Flexibility: The solutions provide seamless scaling and flexibility, enabling users to grow their data extraction capabilities as their data volumes grow and user needs evolve.
- Streamlined Data Pipeline Management: Fivetran, Matillion and Stitch come with built-in monitoring and management capabilities that enable you to keep track of your data extraction pipelines and help you to ensure smooth operations and timely data availability.
The cloud-agnostic nature of these platforms enable organizations to manage their data pipelines across multiple cloud environments from a single, unified interface.
#2. Build a Configuration-Driven, Metadata-Driven Data Extraction Platform
For more complex pipelines that require handling frequently-added or changing structures, consider building a configuration-driven, metadata-driven platform that can auto-generate or auto-update your data extraction pipelines.
For building out your platform, the open-source Airflow library is a strong choice. However, keep in mind that managing Airflow can quickly become complex, particularly when you are managing a high number of pipelines.
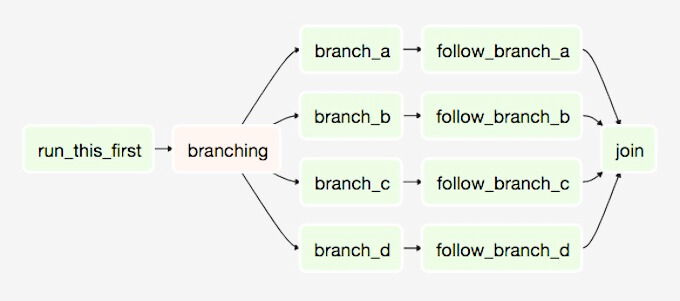
If you choose to go with Airflow, consider opting for a managed Airflow-as-a-Service offering, such as Astronomer Astro.
Google Cloud and AWS also have their managed Airflow offerings, namely Google Cloud Composer and Amazon Managed Workflows for Apache Airflow (Amazon MWAA).
Open-source marketplace alternatives to Airflow include Dagster and Prefect. They each have their managed offerings, namely Elementl's Dagster Cloud and Prefect Cloud.
Interested in building out your custom config-driven, metadata-driven data extraction platform?
We are your perfect solution for building out a custom data extraction platform for your exact data ingestion needs.
We have extensive, cloud-certified data engineering experience building out cutting-edge data platforms and products across several industries.
Speak with a cloud-certified expert to kick off your journey of streamlined data extraction and drive valuable insights that propel your business forward.
#3. Explore AWS Services for Data Extraction
If you prefer to focus on AWS, explore services that can perform data extraction, such as AWS Step Functions, AWS Glue Databrew, AWS Database Migration Service (DMS) and the aforementioned managed Airflow service Amazon MWAA.
#4. Look into Google Cloud Services for Data Extraction
For a Google Cloud-focused solution, look into the services that can perform data extraction, such as Google Workflows, Google Cloud Data Fusion, Google Datastream and Google Cloud's Airflow-as-a-Service offering Google Composer.
Additional approaches to consider when streamlining your data extraction are Change Data Capture (CDC) and Event-Driven Processing.
#5. Integrate Change Data Capture (CDC) Techniques
Change Data Capture is a technique used to track changes in source data and propagate those changes to the target system.
By implementing CDC, you can efficiently capture only the data that has changed or been updated since the last extraction, reducing the amount of data that needs to be processed and improving the overall efficiency of your data extraction process.
Some popular CDC tools and services include Apache Kafka Connect, AWS Database Migration Service (DMS) and Google Datastream.
#6. Consider an Event-Driven Architecture
An event-driven architecture enables data extraction in near real-time as events occur in your source systems.
The event-driven approach minimizes the need for batch data extraction processes and reduces the latency between when data is generated and when it is available for processing.
An event-driven architecture is particularly effective when dealing with data that has varying logic for each row/record/event.
The event-driven architecture's inherent flexibility enables fine-grained processing of individual events with the capability to run events through different streams and/or run a single event through multiple streams, driven by high-granularity logical conditions.
By decoupling components and promoting modularity, event-driven architecture can easily accommodate different processing requirements for diverse data.
A system built on event-driven architecture is more adaptable and scalable, as you can introduce new event types or changes in logic without disrupting the overall architecture or affecting other components.
Tools and services that can help you implement an event-driven architecture include Apache Kafka — including AWS' managed Kafka offering Amazon Managed Streaming for Apache Kafka (MSK) — AWS Kinesis and Google Cloud Pub/Sub.
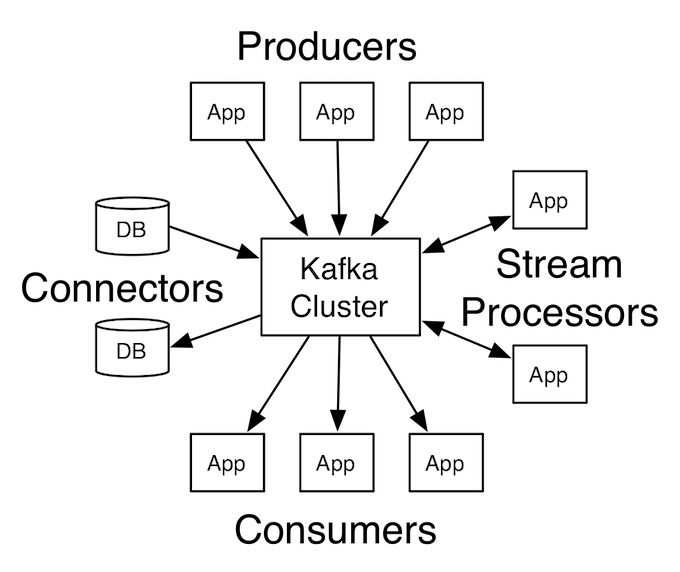
Adopting an event-driven architecture can introduce challenges, such as increased complexity in system design and management due to the asynchronous nature of event processing.
Ensuring data consistency and handling potential errors in a distributed system can also be more difficult.
Additionally, monitoring and debugging event-driven systems can be challenging, as they require specialized tools and practices to effectively track event flows and identify issues.
Conclusion
Tackling the challenge of inefficient data extraction is crucial for ensuring your data engineering pipelines are reliable and scalable.
By leveraging one of the data orchestration platforms available in the marketplace or building out your custom configuration-driven, meta-driven platform, you can streamline your data ingestion and build a strong foundation for high-quality insights and decision-making.
In future blog posts, we'll dive deeper into the differences, pros and cons of the various data extraction solutions mentioned above.
Stay tuned for more blog posts in this series, as we continue to explore key data engineering challenges and solutions.
Are you ready to overcome the challenges of inefficient data extraction and take your data engineering efforts to the next level?
Speak with a seasoned, cloud-certified data engineering expert to kick off streamlining your data extraction and ingestion pipelines today.
We specialize in implementing custom data strategies, state-of-the-art data engineering solutions and industry best practices to optimize your data ingestion processes and enhance the performance of your data extraction pipelines.
Schedule a cloud data strategy and architecture consultation with us today: A cloud-certified data architecture expert will guide you in unlocking the power of the cloud and data to propel your business forward.